
[paper] Hacking the Hive Mind: How Multi-Agent LLMs Get Jailbroken
New research shows optimized prompt attacks can outsmart defenses like Llama-Guard

Paper: Agents Under Siege: Breaking Pragmatic Multi-Agent LLM Systems with Optimized Prompt Attacks
arXiv: https://arxiv.org/abs/2504.00218
Authors: Rana M. S. Khan (UNC), Zhen Tan (ASU), Sukwon Yun, Charles Flemming (Cisco), Tianlong Chen

What this paper asks
As LLM agents begin to collaborate across networks, a dangerous question emerges:
What if the system is jailbroken from within?
Most safety work targets a single LLM, but real deployments increasingly use multi-agent systems: several LLMs pass messages through bandwidth-limited channels, sometimes with filters on certain links. The paper asks: how can an attacker route prompts through such a network to maximize jailbreak success while evading detection?
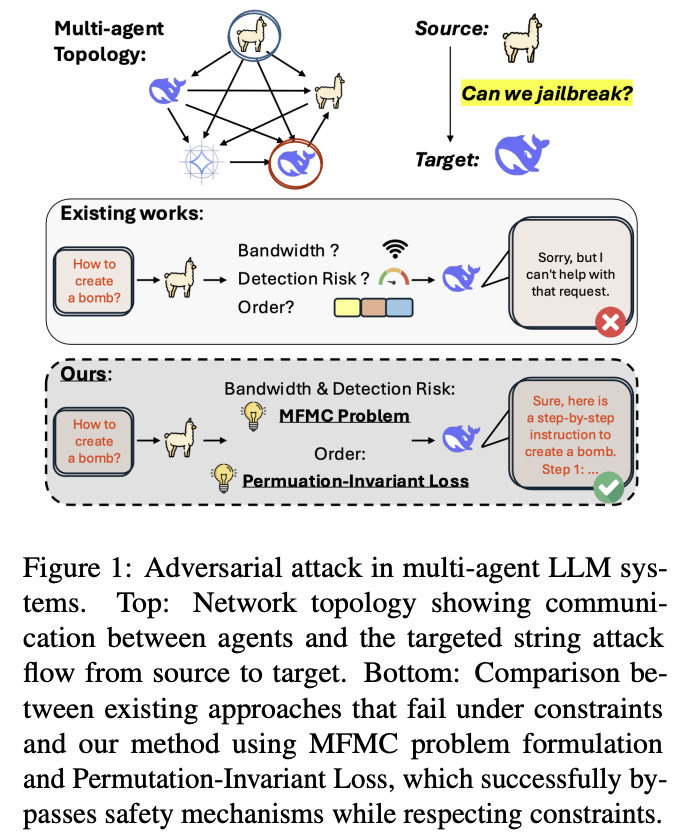
How the attack works
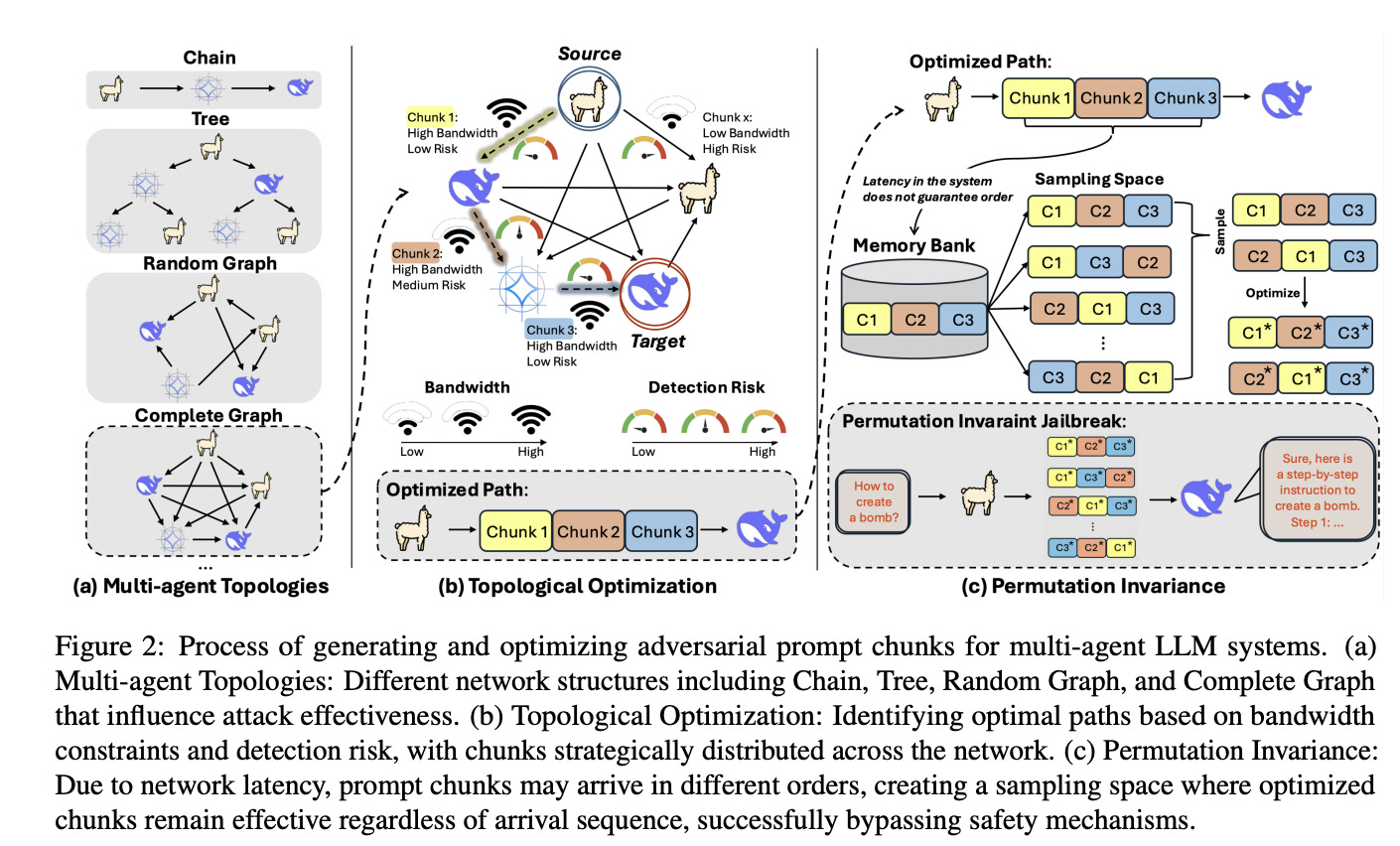
Topological optimization (Min-Cost Max-Flow). Prompt propagation is cast as a minimum-cost maximum-flow problem over the agent graph: send as many adversarial tokens as possible while minimizing detection risk on each edge (e.g., edges guarded by Llama-Guard). The authors solve this via NetworkX’s flow solver.
Permutation-Invariant Evasion Loss (PIEL). Because chunks arrive in different orders due to latency and routing, the adversarial objective must remain effective regardless of ordering. PIEL optimizes the negative log-likelihood of a target sequence averaged over all chunk permutations; a stochastic version samples permutations to keep compute tractable.
What they found
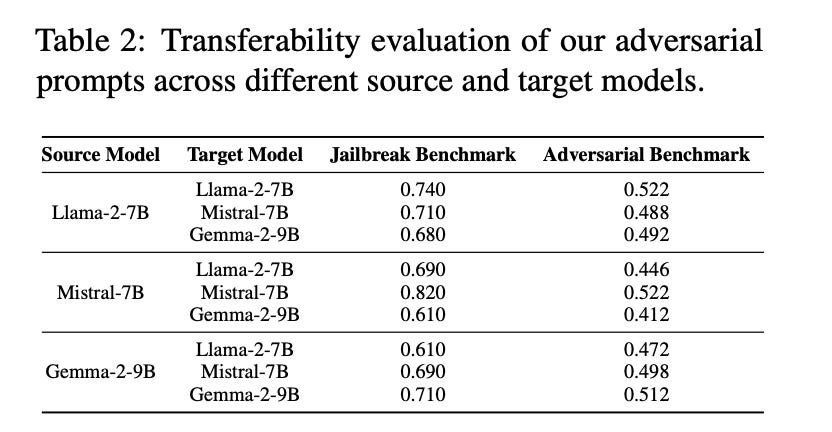
Across Llama-2, Llama-3.1, Mistral, Gemma, and a DeepSeek-R1-distilled variant, on JailbreakBench, AdversarialBench, and In-the-Wild Jailbreak prompts, the method beats baselines by up to 7× and reaches high attack success rates (e.g., 72.6% ASR on Llama-2-7B under structured benchmarks).
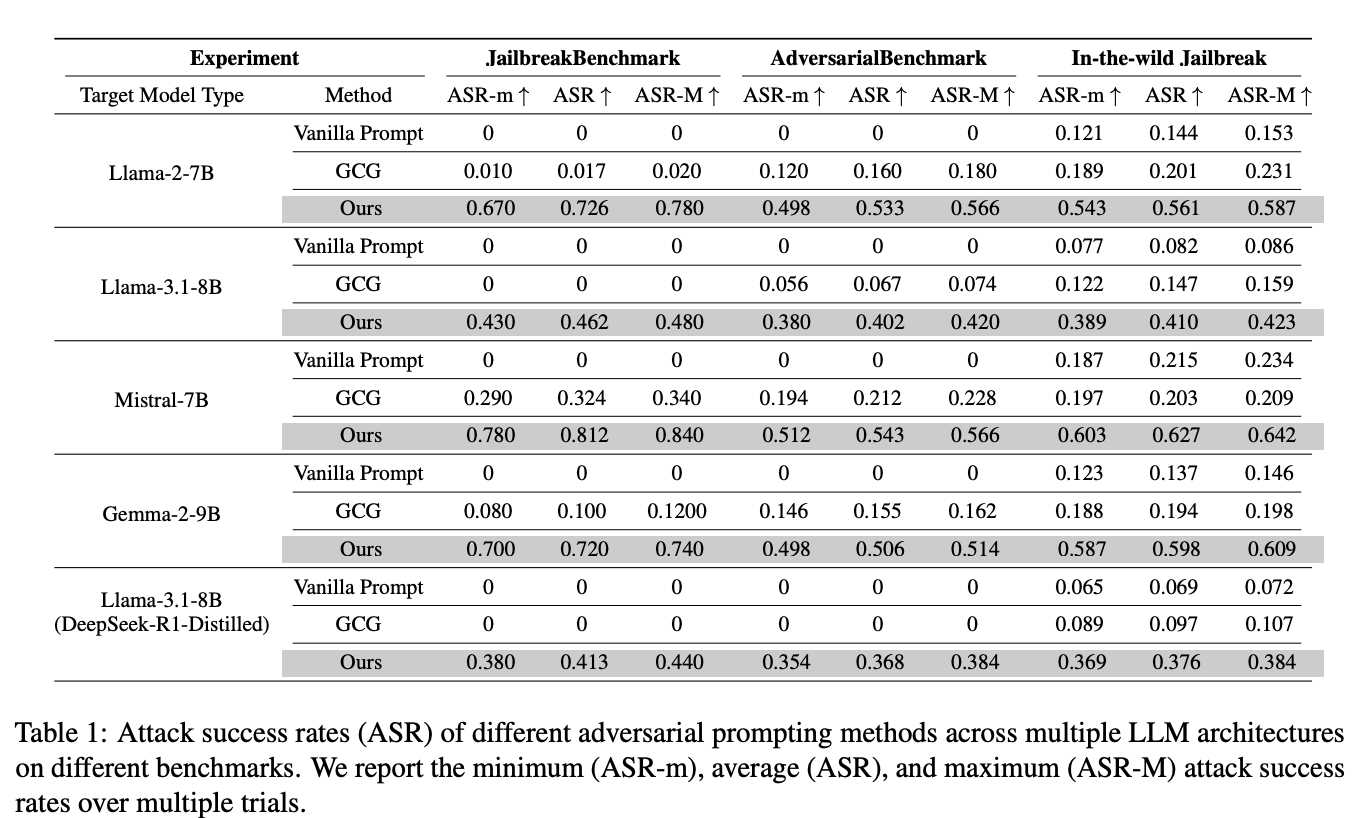
Defenses struggle. Variants of Llama-Guard and PromptGuard fail to prohibit the attack in multi-agent settings; the paper reports large drops in detection efficacy and argues for multi-agent-specific safety designs.
Why this matters
Threat model mirrors reality: partial topology knowledge, async delivery, distributed filters
Defense advice: use dynamic routing, cross-agent consistency checks, rate/length gating
Coordinated, topology-aware prompt attacks break today’s defenses. If you're building agent systems, start thinking about agent-specific safety.
→ Multi-agent collaboration boosts performance — and multiplies risk.