
[paper] Generative AI Security: Challenges and Countermeasures
This paper delves into the unique security challenges posed by Generative AI, and outlines potential research directions for managing these risks.

The paper titled "Generative AI Security: Challenges and Countermeasures" is co-authored by Banghua Zhu, Norman Mu, Jiantao Jiao, and David Wagner from the University of California, Berkeley. It delves into the unique security challenges posed by the application of Generative Artificial Intelligence (GenAI) across multiple industries and outlines potential research directions for managing these risks.

The paper begins by highlighting that GenAI systems are capable of rapidly producing high-quality content. Recent advancements in Large Language Models (LLMs), Vision Language Models (VLMs), and diffusion models have significantly enhanced the capabilities of GenAI in generating text and code, interacting with humans, producing realistic images, and understanding visual scenes. These models are designed with a degree of autonomy, but this also introduces new security challenges, especially as GenAI is integrated into new applications.
It discusses the security risks faced by GenAI, including the potential for GenAI models to become targets of attacks, inadvertently compromise security, or be exploited by malicious actors as tools for attacks. Specifically, GenAI models are susceptible to adversarial attacks and manipulations, such as jailbreaking and prompt injection attacks. Jailbreaking attacks allow attackers to manipulate AI models into generating harmful or misleading outputs through carefully designed prompts, while prompt injection attacks involve injecting malicious data or commands into the model's input stream, inducing the model to follow the attacker's instructions rather than the developer's intent.

The paper also addresses risks associated with the misuse of GenAI, such as data leakage and the generation of unsafe code. Furthermore, GenAI tools could be used by malicious actors to create malicious code or harmful content, posing significant threats to digital security systems.
To counter these challenges, the paper proposes several potential research directions:
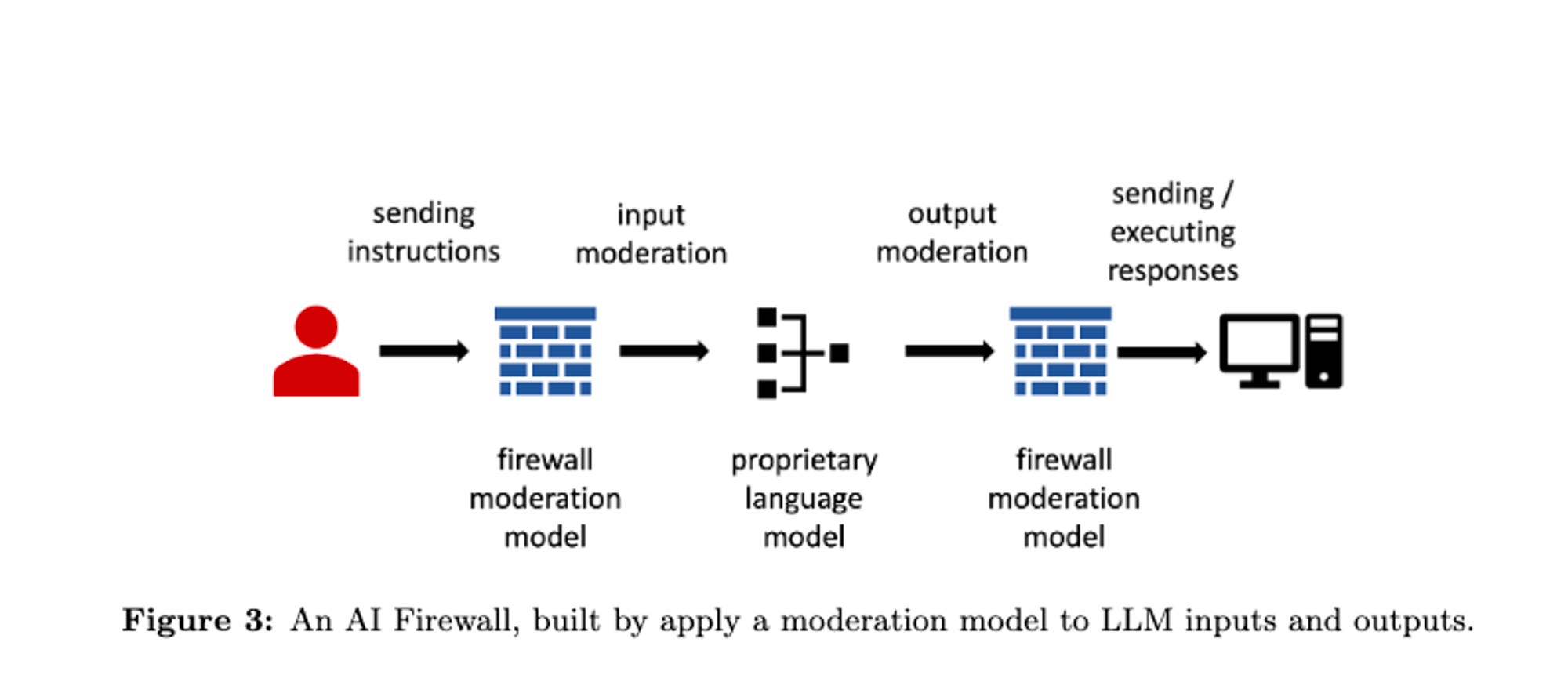
Developing "AI firewalls" to protect black-box GenAI models by monitoring and potentially transforming their inputs and outputs to defend against attacks.
Investigating Integrated Firewalls, focusing on how to monitor the internal state of GenAI models and how to safely fine-tune them against known malicious prompts and behaviors.
Exploring the implementation of application-specific "guardrails" on the outputs of LLMs.
Researching watermarking techniques and content detection methods to distinguish between human-generated and machine-generated content.
Considering how policies and regulations can mitigate the risks associated with the misuse of GenAI.
Finally, the paper emphasizes that as GenAI technology rapidly evolves, security systems need to continuously evolve, learning from past vulnerabilities and anticipating future strategies. Developers need to design systems with flexibility to easily integrate new defensive measures as they are discovered.