[paper]LLM4Decompile: Decompiling Binary Code with Large Language Models
Large language models (LLMs) show promise for programming tasks, motivating their application to decompilation

paper: LLM4Decompile: Decompiling Binary Code with Large Language Models

This paper, titled "LLM4Decompile: Decompiling Binary Code with Large Language Models," is authored by a research team from the Southern University of Science and Technology and The Hong Kong Polytechnic University. The core content of the paper proposes a new decompilation method based on large language models (LLMs) aimed at converting compiled machine code or bytecode back into high-level programming languages. The team found that existing decompilation tools fall short in generating code that is easily readable by humans, particularly in the details of variable names and program structure. Therefore, they developed a new open-source LLM specifically for decompilation and created a dataset named Decompile-Eval to evaluate the re-compilability and re-executability of decompiled code.

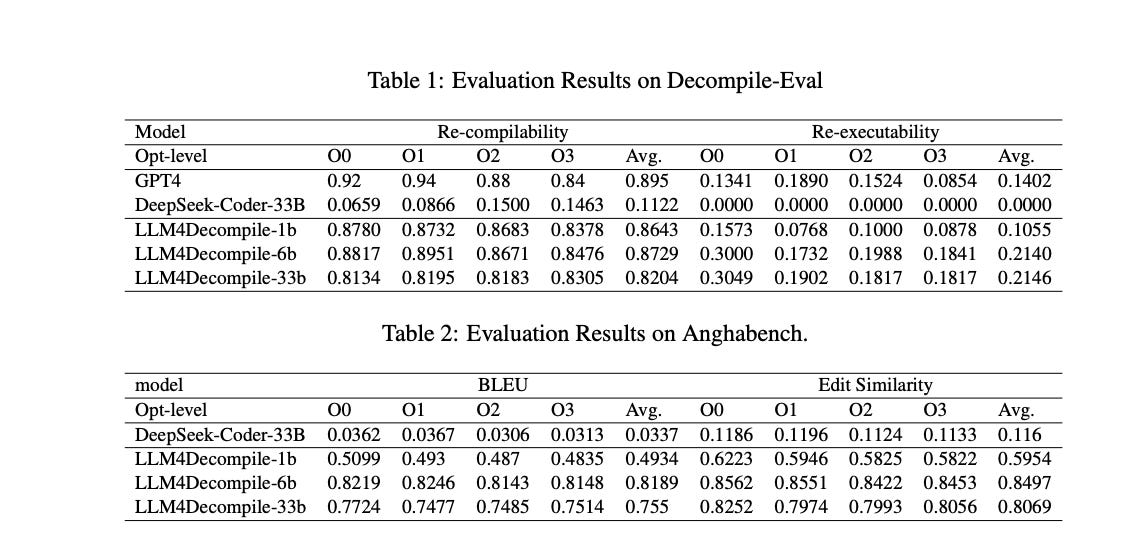
The research team first compiled a million C code samples from AnghaBench into assembly code and paired them with the original C code, constructing a dataset of assembly-source pairs with 4 billion tokens. They then fine-tuned the DeepSeek-Coder model, an advanced code LLM, using this dataset. In this way, they created LLMs of different scales, ranging from 1B to 33B parameters, and tested them on the Decompile-Eval benchmark.
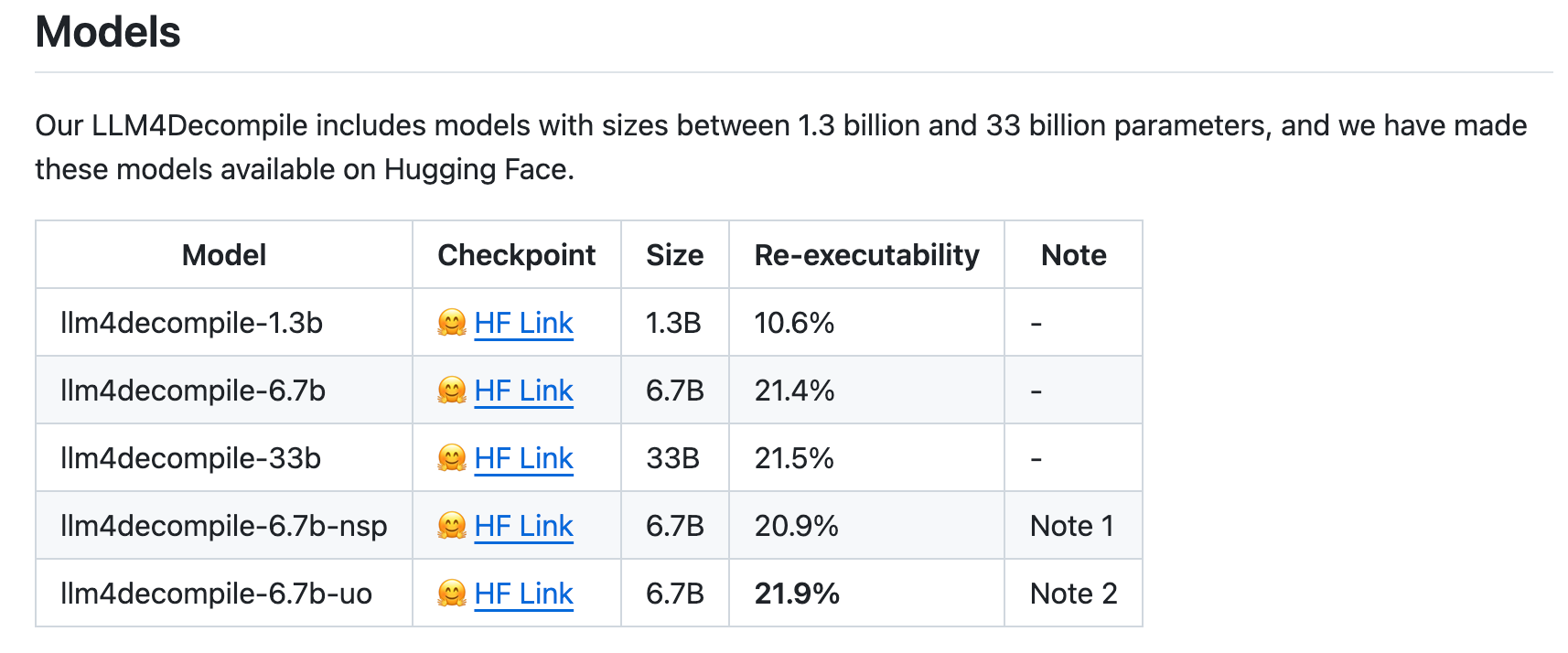
The experimental results show that their LLM4Decompile model excels in decompiling assembly code, achieving an accuracy rate of 21%, which is a 50% improvement over GPT-4. In terms of re-compilability, 90% of the decompiled code can be successfully compiled using the original GCC compiler settings, indicating a good understanding of code structure and syntax. As for executability, the 6B version of LLM4Decompile successfully captures the semantics of the program and passes all test cases, while only 10% of the code from the 1B model can be re-executed.

The paper also discusses related work in the field of decompilation and points out the shortcomings of existing evaluation methods. Traditional decompilation tools rely on pattern matching and control flow analysis, but these methods perform poorly when dealing with optimized code. Neural network-based methods, such as RNNs and Transformer-based models, show potential in decompilation but are limited by model size and public availability. Thus, the team's goal is to create and release the first open-source LLM dedicated to decompilation and build the first benchmark for re-compilability and re-executability.
The conclusion of the paper emphasizes that their work is an initial exploration of data-driven methods in the field of decompilation and establishes an open benchmark to motivate future efforts. The public dataset, model, and analysis represent an encouraging first step towards enhancing decompilation capabilities through novel techniques. However, the research is limited to the compilation and decompilation of C language targeting the x86 platform and only considers the decompilation of single functions, without accounting for factors such as cross-references and external type definitions.
LLM4Decompile Code and Model
code: LLM4Decompile

model: arise-sustech/llm4decompile-6.7b-uo