
[paper]Logits of API-Protected LLMs Leak Proprietary Information
Potential Information Leakage in API-Protected LLMs

In the digital age, the application of Large Language Models (LLMs) has become increasingly widespread, revolutionizing various fields from text generation to automated customer service with their potent capabilities. However, as these models are commercialized, ensuring their security and privacy becomes paramount. The recent paper "Logits of API-Protected LLMs Leak Proprietary Information" by Matthew Finlayson, Xiang Ren, Swabha Swayamdipta, and Thomas Lord highlights a significant security issue: even LLMs accessed through restricted APIs may leak proprietary information.

1. Introduction and Background
The commercialization of LLMs has led to a common practice of limiting access to proprietary models through restricted APIs. This approach might provide LLM providers with a false sense of security, believing information about their model architectures to be private and certain types of attacks on LLMs to be unfeasible. However, this paper demonstrates how a substantial amount of non-public information about an API-protected LLM can be learned through a limited number of API queries (e.g., OpenAI's gpt-3.5-turbo model, costing under $1000).
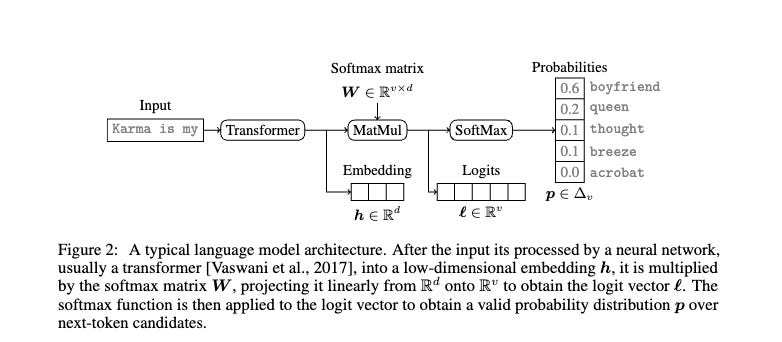
2. Technical Details: The Softmax Bottleneck
The paper's core findings are based on a crucial observation: most modern LLMs are constrained by the softmax bottleneck, which restricts model outputs to a linear subspace of the complete output space. The authors exploit this fact to unlock multiple capabilities, including efficiently discovering the hidden size of LLMs, obtaining cheap full vocabulary outputs, detecting and removing different model updates, identifying the source LLM from a given single complete LLM output, and even estimating output layer parameters.

3. Empirical Study
The authors demonstrate the effectiveness of their method through empirical studies, estimating the embedding size of OpenAI's gpt-3.5-turbo to be around 4096. Additionally, they show high accuracy in using LLM images as unique signatures to identify model outputs, which is very useful for accountability of API LLMs. These signatures are also sensitive to minor variations in LLM parameters, making them suitable for inferring detailed information about model parameter updates.
4. Applications and Impact
The paper explores multiple applications of leveraging LLM images, including:
- Rapid acquisition of complete LLM outputs.
- Discovering the embedding size of LLMs and guessing their parameter counts.
- Identifying which LLM produced a given output.
- Detecting and pinpointing the timing and nature of LLM updates.
- Finding tokenization errors (non-argmax tokens).
- Approximating the reconstruction of LLM's softmax matrix.
- Cheaply and accurately reconstructing "hidden prompts".
- Implementing evidence-based decoding algorithms.
5. Mitigation Measures
The paper also discusses several mitigation measures that can be taken by LLM providers, as well as how to view these capabilities as features rather than flaws by allowing greater transparency and accountability.

6. Conclusion
The authors argue that their proposed methods and findings do not require a change in the best practices of LLM APIs but rather expand the tools available to API clients, while cautioning LLM providers about the information their APIs expose. Although these findings may lower the cost of model stealing methods that rely on complete outputs, the authors believe the benefits of these methods for API clients outweigh any known harms to LLM providers.
7. Concurrent Discoveries
Interestingly, a method very similar to the one proposed in the paper was also put forward by Carlini et al. in 2024, highlighting the urgency and relevance of the research.
8. Summary
This paper provides a deep insight into the potential information leakage in API-protected LLMs and proposes a range of possible solutions and applications. As the application of LLMs continues to grow across various fields, ensuring their security and transparency becomes increasingly important. This research is not only significant for developers and providers of LLMs but also represents an important contribution to the entire artificial intelligence community and industries reliant on these models.